求解网络安全问题的可解释机器学习
本文的所有内容与作者的日常工作无关,其观点也仅代表作者个人意见,与作者的雇主无关。
小朋友,你是否有很多问号,为什么过年回来发现模型预测性能下降?为什么总有几个样本拉低模型性能?为什么收集了运营同事反馈的坏样本也找不到模型错在哪?如是这些问题在提醒我们可能需要可解释机器学习模型,它在一定程度上提供了人类可以理解的方式理解在某个样本上模型到底做了什么事。
在网络安全领域里,模型预测结果的可解释性与运营紧密相关,例如防火墙类产品需要预测结果有足够的置信度从而阻断威胁,云上 SIEM 和 SOAR 系统也需要引入预测结果的具体原因和上下文关联等辅助运营判断。从模型本身的可解释性出发,我们可以为预测结果提供部分的可解释性以支持运营。
学界对可解释人工智能(XAI)及其子方向可解释机器学习进行了多个角度的研究,本文从网络安全中最让人头疼的流量检测的例子出发,简单介绍黑盒可解释模型及其在工业界的一些方法和应用,包括其设计思路、使用方法和局限性等等,各位小伙伴们可以此对这一研究课题展开进一步探索。
以加密流量分类为例,感受“可解释”机器学习
网络安全业界有很多基于统计特征作流量检测和分类的机器学习模型,例如之前一篇检测加密 DNS 的文章中的介绍的基于流量包特征的检测模型。这类由固定数据集得到的频率统计特征难以泛化到一般情况,这些稠密的特征在例如 xgboost 等较强的学习器下被精细切分以判别结果,但是基于 boosting 的切分方式难以控制,切分的越精细其对未知数据的泛化危险越高。相比于其在固定数据集得到的纸面上优异的结果,它们部署在生产环境后的长期表现也让人头疼,模型性能的下降以及数据特征的不稳定要求构建模型的数据科学团队不断的投入精力维护,甚至让数据团队逃避解决流量检测类的问题。这里网络安全里让人头疼的问题恰好可以用可解释机器学习有效的解决。
补充一点,业界对此类问题有多种处理办法,例如 He et al
*“Practical Lessons from Predicting Clicks on Ads at Facebook” 的文章利用决策树将稠密的特征分成稀疏的向量并用简单线性模型求解,它在一定程度上控制了统计特征的切分;也有跳出统计特征,直接将原始流量数据输入给深度神经网络以提取特征,然而神经网络不能保证合理的抽取特征并足够泛化,同时,这些网络中常见的用于判别的全连接层的设计往往只是照搬其他图形类的方案,其表现多数情况下不如决策树分类器。
我们使用 SHAP (SHapley Additive exPlanations)算法*切入这一问题。SHAP 算法从博弈论的角度出发试图解决这样一个合作竞争的经济学问题:假设 A B C 三人合作得到的 1000 元奖金,如何合理衡量各自贡献并分配奖金?在这里“合理衡量”需要考虑到三人的独立贡献、俩俩合作(包含前后顺序)、三人合作、俩俩合作与三人合作的关系等。SHAP 算法将模型的输入特征类比于合作的个体,其可解释的贡献值脱胎于 Shapley value * 这一获得2012年诺贝尔奖经济学奖的研究方向,实际计算中需要考虑到贡献人(特征向量)的各种组合,所以其精确解的计算复杂度是 NP hard,SHAP 算法通过线性约束的办法在有效的时间内逼近了较好的结果,各位如果有兴趣的话可以认真读一下参考文献中这篇有意思的论文。
在实际应用中,SHAP 的开源实现根据不同类型的预测模型做了特定优化,比如决策树类模型可以使用 Tree SHAP 的优化版本。例如检测加密 DNS 的 xgboost 模型即可通过简单添加这几行代码即可使用 SHAP 解释其预测结果:
import shap
explainer = shap.Explainer(clf.best_estimator_)
shap_values = explainer(train[features])
# visualize the first prediction's explanation
shap.plots.waterfall(shap_values[0])
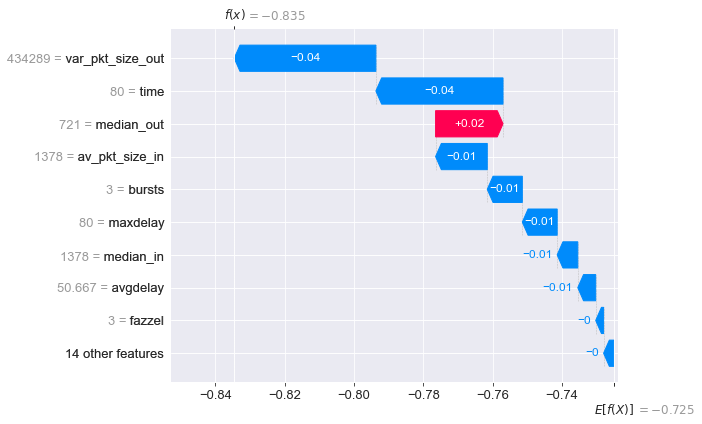
从以上 SHAP 值的瀑布图(Waterfall)中可以看到数据集中所有样本的期望为 -0.725 而模型对 0 号样本预测值为 -0.835,它是因为 var_pkt_size_out time 等特征将其从所有样本的期望 -0.725 推向 -0.835,而 median_out 将预测结果拉回所有样本的期望,随着拉扯的力量不同,模型对 0 号样本最终得到 -0.835 的预测结果,并成功预测其为负样本(非加密 DNS)。
对于第 33 号正样本(加密 DNS ),median_out 和 median_in 对于其偏离所有样本的期望作出了重大贡献,一举将其预测值拉到 -0.187 并成功预测其为正样本。
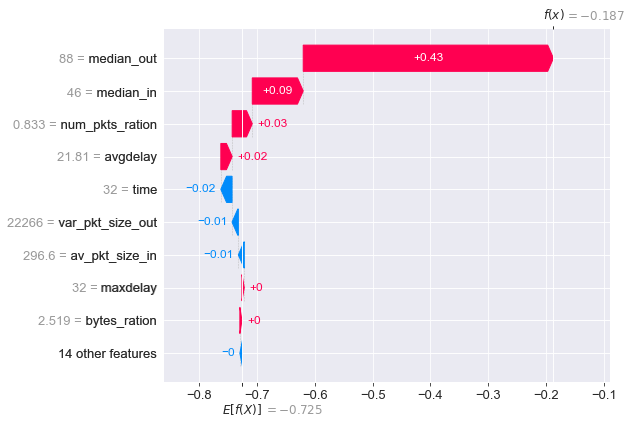
median_out 和 median_in 这两个特征在该数据集里多数正样本的判别里也起到决定性作用,同样,var_pkt_size_out 是多数负样本判别的决定性特征。这一解释为使用该模型的方法提供决策依据:部署模型时需要严格监控针对这三个特征的对抗,例如
- 是否存在某种加密 DNS 服务通过混淆的形式扰乱
median_out和median_in这两个统计特征以逃逸检测 - 在设计数据采集场景中是否包含了对
var_pkt_size_out等特征的选择偏向 - 这些起决定性作用的特征在不同时间段采集的数据中是否保持一致的统计分布
其中“起决定作用的特征的统计分布的改变”是导致模型部署和上线后性能下降的主要原因之一,它属于数据漂移(data drift)的一种,找到这些特征并监控其分布可以有效发现并及时处理。各位小伙伴可以继续探索使用 SHAP 的 force_plot 等其他功能进一步了解模型的判别依据。当然,大家可以自行参考原文附带的 Jupyter Notebook 查看各个样本的 SHAP 瀑布图,也可以调整预测模型的参数观察新参数下 SHAP 瀑布图的变化。
以上 SHAP 的例子展示了黑盒可解释机器学习模型的一般使用办法,它们基本遵循如下特性:
- 模型流程需要先有预测模型,再拿一个模型去解释它,称之为”事后解释“(post hoc)
- 该解释模型总是提供解释,但并不关心预测方法以及结果是否正确
- 该解释模型针对每个样本产生 SHAP 值的瀑布图,而非对数据集的整体解释
类似于 SHAP 这样事后黑盒解释判别模型的方法还有 LIME * 等,有兴趣的小伙伴可以参考 “Interpretable Machine Learning” 这本书进一步学习。
都有了特征权重,还需要可解释模型么?
各位小伙伴们可能会问,SHAP 值与特征权重(permutation feature importance)有什么区别呢?每个特征的 SHAP 值与每个样本相关,它描述了特征组合在判别该样本上的边际效应,正样本负样本的特征组合与其边际效应都可能不同,而特征权重描述的是模型对整个数据集的整体认识,它描述的是模型对该数据集的判别表现,与具体样本无关。我们可以利用 SHAP 值在不同样本上的分布作特征选择以提高模型特性,也可以通过理解 SHAP 值的分布优化调整 Kaggle 比赛的模型*,请各位小伙伴自行参考 SHAP Summary Plot 和 Dependence Plot 等。
当然,SHAP 并非是可解释机器学习的唯一办法,在通向可解释性机器学习和 XAI 的道路上,我们有很多选择。
部分模型天生具有可解释性,比如基于符号的人工智能模型*例如逻辑推理等,其结果即可自我解释,这也是之前博客中提到本文作者团队去年发表的工作 “Honeypot + graph learning + reasoning = scale up your emerging threat analysis” 利用了逻辑推理的模型解释另一个分布式嵌入模型的结果;又比如 Logistic regression 和线性回归的结果也是由单一权重矩阵表示,它本身也自带可解释性;kNN 模型的结果也是可以自我解释。
用于解释别的模型的可解释模型也分成类似 SHAP 和 LIME 等的通用模型,以及一些特殊场景模型,例如注意力(attention)机制对 BERT/GPT 等 transformer 家族的模型结果可以提供一定的解释,最近 Deepmind 的 AlphaCode 在其 demo 中*利用注意力机制解释其生成的竞赛代码结果的依据;一些对抗生成模型(GAN)以扰乱模型判别而产生的对抗样本也在一定程度上揭示了判别模型内在的缺陷或隐含假设等潜在问题。
在参考文献中列出的Explainable AI Cheat Sheet * 为现有的可解释人工智能模型提供了很好的综述,请各位小伙伴自行阅读探索。
请保持冷静:都有了可解释模型,还需要其他么?
可解释模型有着天然的局限性:它的视野局限于解决眼前的问题,它不能跳出定义的问题和数据集之外。在网络安全的场景里,由于数据采集和检测场景的局限,外加攻击方会使用千奇百怪的方式试图隐藏其行为,寻找外部因素和内部因素同样重要。可解释模型不会告诉我们出现 C&C 行为的原因来自于一个未知的 0day 漏洞,或者是一个没有日志记录而悄悄创建的管理员账号。同样,SHAP 等可解释模型不等于可解释结果,对不同场景解释预测结果可能需要针对结果的可解释模型,以及模型之外的第三方知识或者日志等。
可解释模型只是“解释”而不是“因果”,我们仍然需要因果推断。更重要的是,可解释模型仅停留在“解释”而非逻辑论证:它不保证模型结果正确,它也不保证其解释符合逻辑,它仅仅是尽其所能解释 A 模型在 X 样本上为什么这么判断。一个常见的例子是肿瘤样本与尺子的笑话 *,当模型把只存在于正样本图片里的尺子当作肿瘤的重要特征,其解释模型也仅能指出“它认出了这把尺子”而不能表达“尺子并非合理的判断依据”。数据科学团队仍然需要自行发现问题、逻辑论证并改进模型。
在工业界里,我们也必须提到的可解释模型的成本。事后解释模型提供的可解释性伴随着额外的开发部署等工程成本,它同时也有使用场景的局限性,很多情况并不需要可解释机器学习也可以做得很好。请各位小伙伴考虑到运营成本与可解释模型成本的平衡,自行斟酌是否需要可解释模型。
总结
可解释机器学习在一定程度上有助于解决网络安全在动态环境下带来的若干问题,不仅可以提供解释结果辅助运营,同时也可以帮助数据科学团队有效的长期维护模型的稳定表现。本文从工程案例的角度介绍可解释机器学习的使用方法,因为篇幅所限而特意忽略了具体的理论知识,这并不代表这些理论基础不重要。
参考文献
- He et al, Practical Lessons from Predicting Clicks on Ads at Facebook https://quinonero.net/Publications/predicting-clicks-facebook.pdf
- SHAP paper, Lundberg and Lee “A Unified Approach to Interpreting Model Predictions” https://proceedings.neurips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html
- Shapley value https://en.wikipedia.org/wiki/Shapley_value
- SHAP in “Interpretable Machine Learning” https://christophm.github.io/interpretable-ml-book/shap.html
- SHAP github https://github.com/slundberg/shap
- LIME https://github.com/marcotcr/lime
- Kaggle post “Advanced Uses of SHAP Values” https://www.kaggle.com/dansbecker/advanced-uses-of-shap-values
- Symbolic artificial intelligence https://en.wikipedia.org/wiki/Symbolic_artificial_intelligence
- AlphaCode demo https://alphacode.deepmind.com/
- Explainable AI Cheat Sheet https://ex.pegg.io/
- Please Stop Doing “Explainable” ML - Cynthia Rudin https://www.youtube.com/watch?v=I0yrJz8uc5Q
- When AI flags the ruler, not the tumor https://venturebeat.com/2021/03/25/when-ai-flags-the-ruler-not-the-tumor-and-other-arguments-for-abolishing-the-black-box-vb-live/