从流量中检测加密DNS
本文的所有内容与作者的日常工作无关,其观点也仅代表作者个人意见,与作者的雇主无关。
问题背景
DNS 作为互联网运营商和各大云厂商把持流量数据的基础设施之一,一直备受大小算法模型工作团队的宠爱,毕竟是加密流量时代还能推测一个HTTPS的网址指向哪个网站的一股清流。加密流量时代也在发展,随着 DNS-over-HTTPS (DoH) 与 DNS-over-TLS (DoT)争当业界标准时抱住了谷歌的大腿,就好比新浪微博悄悄注册了“微博”一样,DoH 悄悄地自封为业界标准。DoH 与 DoT 诸多不同里最重要一点是 DoT 使用独立的 853 端口而 DoH 与 HTTPS 一样都是 443 端口,人为的给恶意流量检测和内容分发控制造成了困难:如何在 HTTPS 流量里检测加密 DNS 流量?
有聪明的小伙伴们会说,向各个提供 DoH 服务的网站提交 HTTPS 请求的时候也会触发 DNS 请求,比如 https://cloudflare-dns.com/dns-query?name=example.com&type=AAAA 会有 cloudflare-dns.com 这个请求,我们收集所有提供 DoH 服务的地址可用做 DoH 检测。这个思路合理且部分有效,不过在强对抗环境下,谨慎的攻击者可以用这个不会触发DNS请求的查询:
curl -H 'accept: application/dns-json' 'https://1.1.1.1/dns-query?name=example.com&type=AAAA'
{"Status":0,"TC":false,"RD":true,"RA":true,"AD":true,"CD":false,"Question":[{"name":"example.com","type":28}],"Answer":[{"name":"example.com","type":28,"TTL":78405,"data":"2606:2800:220:1:248:1893:25c8:1946"}]}%
关于 DoH 流量检测在最近有一些尝试,本文讨论的这篇论文提供了一个不错的学术数据集以及初步探索 “DoH Insight: Detecting DNS over HTTPS by Machine Learning” https://sappan-project.eu/wp-content/uploads/2020/09/DOH-2.pdf (以下简称“论文”)。 本文从论文的思路出发验证其结果,并由此展开一些关于流量检测的讨论。本文使用的实验代码可以在 https://github.com/phunterlau/code-in-blog/tree/main/doh 获取,欢迎 fork。
复现与分析
论文在受限的环境里模拟了日常个人电脑通过常用软件比如 Firefox 访问 HTTPS 网站时包含的 DoH 流量,它的数据分布也较好的模拟了这种场景,约小于10%的HTTPS流量为 DoH。作者也根据连接时长、延迟、包的尺寸和数量等做了不错的特征工程,并公布了数据集。论文中的初步结论为,连接时长和延迟两类特征可以有效帮助判别 DoH 流量以及使用该流量的客户端软件。
特征分析
数据集中 DoH 于正常 HTTPS 的流量分布并不均衡,它很好的反映了现实情况,不过在交叉检验的时候需要 RepeatedStratifiedKFold,它在这种非平衡数据的情况更好的反映评估结果:
df_train['is_doh'].value_counts()
0 452626
1 34195
Pandas 的 pivot table 是个快速观察每个特征对结果区分影响的好办法。比如连接时长对于是否 DoH 的判断可以简单直观的表达为
df_train_wide=df_train.pivot(columns='is_doh', values='time')
df_train_wide.plot.hist(bins=100, figsize=(8,6), alpha=0.7, log=True)
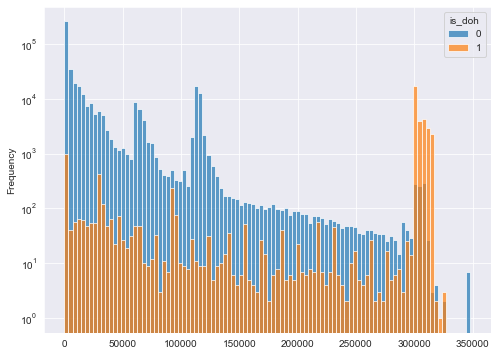
因为正例太少,在这里用对数坐标。大家也可以把 values='time' 替换为别的特征,延迟、包的尺寸和出口入口的其他特征均有一定的判别能力。
模型和参数
论文中实验了kNN和几种决策树。我们用工业界偏爱的 xgboost,并按照论文提示的较浅的树和简单的boosting,暴力搜索一下最好的参数范围并验证论文结果。在这里我复用了之前在 Kaggle 上发表的 xgboost 参数搜索模版以展示参数搜索的细节,而更加现代的工业化做法是使用 AutoML,比如 AutoGluon https://auto.gluon.ai/stable/index.html ,各位小伙伴可以自行探索。
请注意这个数据集的 datasrc 指的是使用的客户端软件,它作为另一个分类任务的label,需要从有效特征里剔除。
train = df_train.drop('datasrc', axis=1)
features = list(train.columns[1:])
import xgboost as xgb
xgb_model = xgb.XGBClassifier()
parameters = {'nthread':[1],
'objective':['binary:logistic'],
'learning_rate': [0.05],
'max_depth': [5,6],
'min_child_weight': [11],
'subsample': [0.8],
'colsample_bytree': [0.7],
'n_estimators': [5,10],
'missing':[-999],
'seed': [1337]}
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
clf = GridSearchCV(xgb_model, parameters, n_jobs=4,
cv=cv,
scoring='roc_auc',
verbose=2, refit=True)
clf.fit(train[features], train["is_doh"])
print("Best parameters set found on development set:")
print(clf.best_params_)
print("Grid scores on development set:")
means = clf.cv_results_['mean_test_score']
stds = clf.cv_results_['std_test_score']
for mean, std, params in zip(means, stds, clf.cv_results_['params']):
print("%0.3f (+/-%0.03f) for %r"
% (mean, std * 2, params))
0.999 (+/-0.001) for {'colsample_bytree': 0.7, 'learning_rate': 0.05, 'max_depth': 6, 'min_child_weight': 11, 'missing': -999, 'n_estimators': 10, 'nthread': 1, 'objective': 'binary:logistic', 'seed': 1337, 'subsample': 0.8}
从这里可以观察到,即使是一个比较浅的决策树( 'n_estimators': 10),它可以达到的 roc_auc 已经很高,对于该结果的特征重要性的分析也可以看到连接时长和延迟等特征对分类结果有重要贡献,这一点也符合论文的结论。
sns.barplot(x=clf.best_estimator_.feature_importances_,y=features)
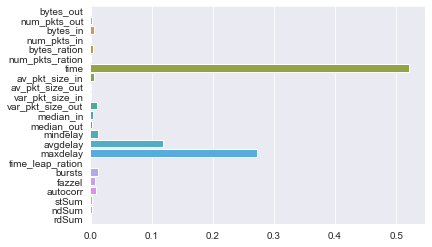
进一步探索
论文在结束时讨论了这种检测方法的局限,除了依赖于统计特征而不能检测单条 DoH 查询之外,对于检测结果对特征的依赖也有所顾虑,包括攻击者可以通过混淆的办法改变连接时长和延迟等特征。我们按照这个思路,尝试把这些强分类的特征丢弃,看看能不能也得到可用的结果。
train_drop = df_train.drop(['datasrc','time','maxdelay','avgdelay','mindelay','bursts','fazzel'], axis=1)
features_drop = list(train_drop.columns[1:])
在丢弃几个高贡献的特征之后,xgboost依然可以搜索到一组足够强的参数并达到较高的 roc_auc 分值。具体搜索代码请看链接的 notebook:
...similar xgboost parameter scanning...
0.999 (+/-0.001) for {'colsample_bytree': 0.7, 'learning_rate': 0.05, 'max_depth': 6, 'min_child_weight': 11, 'missing': -999, 'n_estimators': 5, 'nthread': 1, 'objective': 'binary:logistic', 'seed': 1337, 'subsample': 0.8}
新的特征重要性分析如下
sns.barplot(x=clf.best_estimator_.feature_importances_,y=features_drop)
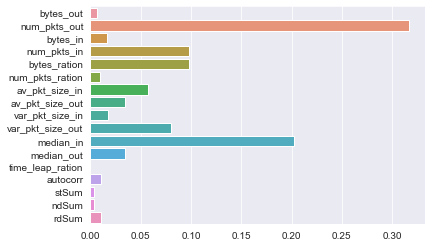
可以看到,在没有连接时长和延迟等易被混淆攻击的特征时,出入口的包特征加上xgboost的强大的学习威力,我们依然可以得到一个适用于该数据集的分类模型。如果想进一步探索更加稳定的特征组合,我们可能需要独立采集的可能含有攻击混淆流量的测试数据集,以验证其在真实环境下的可靠性,而非在此固定数据集里可能由xgboost的强大学习能力带来对该训练数据集的过拟合。
关于论文中另一个实验,对客户端的预测,其结果类同,在此不再赘述,请有兴趣的小伙伴自己探索。
关于流量检测的讨论
流量检测一直是网络安全里的一个重要话题,大多数研究课题集中于“是否包含某种流量”以及按照客户端的流量分类。现有的方法除了本次讨论的统计特征的办法之外,深度学习等擅长于自动特征学习的办法在最近几年也有一定效果。流量检测作为一种单点检测手段也有自己的局限性,基本上是 99.9% 准确度在大流量下的运营成本,模型的在离线检测与在线检测时的工程挑战,以及数据集以及对抗方法后如何更新迭代已上线的模型。除了这三个问题,单纯的流量检测也因为其可解释性对运营带来困扰,特别是在运营商或者云平台等大规模工业化部署。
如果有小伙伴需要在工业环境下构建类似的检测系统,在实际使用中也需要其他方面的独立数据或模型当作辅助判断,例如文章开始说到的收集提供 DoH 服务的域名,或者像各种SASE产品一样在用户的机器上装个记录命令行或者干脆装个公司证书也是可以考虑的。