The Blessing of Dimensionality: How TurboQuant Uses the JL Lemma to Compress KV Caches with Zero Bias
If you are running local LLMs, you already know the bottleneck isn’t compute; it’s memory. Specifically, the KV cache. As your context window grows, storing Keys and Values for every token eats your VRAM alive. On a standard 16GB consumer GPU, you are typically hard-capped around an 8K context length after loading the model weights.
Standard quantization (like INT4 or FP8) helps, but it introduces a fatal flaw: deterministic bias. When you round a vector down to a lower precision, the errors accumulate, distorting the delicate attention matrix and crippling the model’s reasoning capabilities at long contexts.
Enter TurboQuant. By leveraging a beautiful piece of high-dimensional geometry known as the Johnson-Lindenstrauss (JL) Lemma, TurboQuant compresses the KV cache down to 3 bits (or even 2 bits) with practically zero accuracy loss. It achieves a 5x memory reduction without retraining, turning that 8K context ceiling into a 40K playground on the exact same hardware.
The secret isn’t just compression; it’s unbiased compression. To understand why it works so flawlessly, we have to trace the math back to its bedrock.
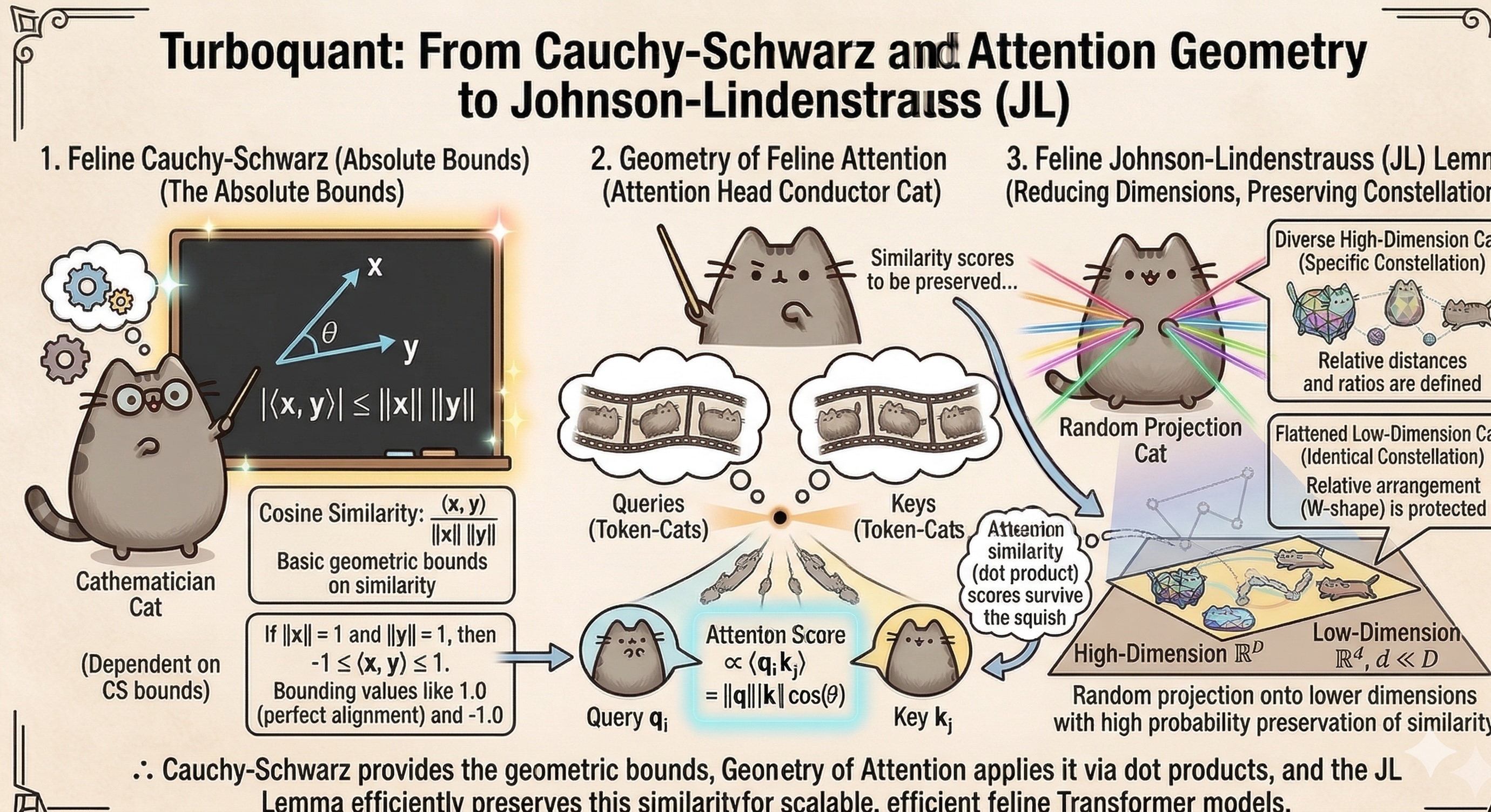
The Anchor: Cauchy-Schwarz and the Geometry of Attention
To understand the elegant hack of TurboQuant, we have to stop thinking of Attention as a sequence of matrix multiplications and start looking at it as a measure of geometric similarity.
The core of the Transformer’s attention mechanism relies entirely on the inner product between a Query vector and a Key vector. This relationship is governed by the absolute dictator of inner products: the Cauchy-Schwarz inequality.
\[|\langle q, k \rangle| \leq \|q\|_2 \|k\|_2\]In a high-dimensional space (e.g., 4096 dimensions), Cauchy-Schwarz dictates that the dot product is maximized when the vectors are perfectly aligned, and becomes zero when they are perfectly orthogonal. This geometric alignment is exactly what the Softmax function turns into an “Attention Score.” If you destroy this geometric relationship by clumsily rounding the numbers, the model hallucinates.
The Chasm and The Bridge: The Polarization Identity
We want to squash our 4096-dimensional vectors down to a much smaller size (say, 256 dimensions) to save VRAM.
The Johnson-Lindenstrauss (JL) Lemma is famous for proving that you can project points into a lower dimension using a completely random matrix, and the Euclidean distances between those points will be preserved. But here is the catch: the Transformer doesn’t compute Euclidean distances. It computes inner products.
How do we bridge the gap between preserving distances (JL) and computing attention scores (Cauchy-Schwarz)? We use a beautiful piece of algebra called the Polarization Identity:
\[\langle q, k \rangle = \frac{1}{4} \left( \|q+k\|_2^2 - \|q-k\|_2^2 \right)\]This identity is the “aha!” moment. It proves that a dot product is not some separate, mystical property—it is literally just a function of lengths and distances. It expresses the inner product entirely in terms of the squared distances of the sum and difference of the vectors.
The Leap: Applying the Random Shadow
Now the trap is sprung. We introduce a random projection matrix $\Phi$ that squashes our vectors from a high dimension $d$ down to a lower dimension $m$. Because this projection is a linear operation, we know that $\Phi(q+k) = \Phi q + \Phi k$.
The JL Lemma guarantees that our random shadow $\Phi$ perfectly preserves Euclidean lengths with exponentially high probability:
\[(1-\epsilon)\|x - y\|_2^2 \leq \|\Phi x - \Phi y\|_2^2 \leq (1+\epsilon)\|x - y\|_2^2\]If JL preserves the lengths of $|q+k|_2$ and $|q-k|_2$, then according to the Polarization Identity, it mathematically must preserve the inner product $\langle q, k \rangle$. The deterministic bounds of Cauchy-Schwarz are perfectly protected by the probabilistic bounds of the JL Lemma.
The QJL Innovation: 1-Bit Unbiased Estimation
Standard quantization methods (like rounding to the nearest integer) introduce bias. They systematically shift vectors in a specific direction.
TurboQuant utilizes Quantized JL (QJL), which takes this random projection one step further. Instead of storing the exact projected values, it stores only the sign of the projection, turning the Key into a tiny 1-bit vector:
\[h(k) = \text{sign}(\Phi k)\]Because the projection $\Phi$ is completely random and data-oblivious, the errors introduced by taking the sign are evenly distributed. This makes QJL an unbiased estimator. In statistical terms, the expected value of our compressed dot product perfectly matches the true dot product:
\[\mathbb{E}[\widehat{\langle q, k \rangle}] = \langle q, k \rangle\]TurboQuant achieves its “zero accuracy loss” by applying this 1-bit unbiased QJL code specifically to the residual error left over after a standard coarse quantization. The math preserves the exact geometry, which in turn preserves the model’s reasoning.
The Magic of the Logarithmic Scale
If you want to find the true elegance of this approach, look closely at the scaling law it produces. To preserve the geometric structure of $N$ tokens in the KV cache with an error tolerance of $\epsilon$, the target dimension $m$ must scale according to:
\[m = \mathcal{O}\left(\frac{\log N}{\epsilon^2}\right)\]Notice what is missing from that equation: the original dimension $d$.
The memory footprint required to preserve the attention matrix is bottlenecked only by the number of tokens in your context window ($\log N$). It completely decouples the memory requirements of the KV cache from the width of the model’s architecture.
Because it scales logarithmically, jumping from an 8K context window to a 40K context window only requires a tiny, incremental bump in the projection dimension. By anchoring its logic in Cauchy-Schwarz and exploiting the dimensional shortcuts of the JL Lemma, TurboQuant turns an intractable hardware limit into a solved geometric puzzle.
Final Thoughts and the Future: Randomness is the Answer
If I have one takeaway from this work, it is that unbiased estimation is not optional for low-bit quantization. Standard quantization methods (rounding) are a blunt instrument that creates systematic biases, which destroy the delicate attention matrix. By combining coarse quantization for low variance and unbiased QJL residual coding for zero bias, TurboQuant achieves a flawless balance.
This highlights the true gift of high-dimensional geometry: the Concentration of Measure. When you have thousands of redundant dimensions, pure randomness ceases to be noise; it becomes a statistically reliable tool. The large dimension $d$ makes it mathematically probable that a random projection $\Phi$ works. The path forward for memory optimization isn’t just about shrinking the precision; it’s about squashing the dimension, while protecting the relative geometry.
Implications & Future Horizons
The immediate practical implication is the democratization of long-context LLMs. Massive models can now be run locally with large context (80k+) on a standard 16GB or 24GB consumer GPU. But this work can inspire even deeper changes:
Hardware for Randomness: Our current GPUs are optimized for deterministic floating-point arithmetic. Could we see hardware accelerators in the future with dedicated modules for fast, on-the-fly random projections?
Unbiased Everything: Is there a way to adapt this residual QJL framework to weights or activations? While those are dynamic and harder to compress offline, the focus on preserving unbiased statistical correctives could change how we approach low-bit model execution.
Ultimately, TurboQuant shows us that the Transformer is far more robust than we believed. Its internal representation is resilient to extreme compression, provided we don’t break the geometric rules that define its reasoning. We can let the model forget the absolute, as long as we help it remember the relationships. That is the final lesson of Cauchy-Schwarz and the JL Lemma.