Linkedin spam: a case study of robust feature engineering
Disclaimer: Nothing in this blog is related to the author’s day-to-day work. The content is neither affiliated nor sponsored by any companies. I am not employed by Linkedin.
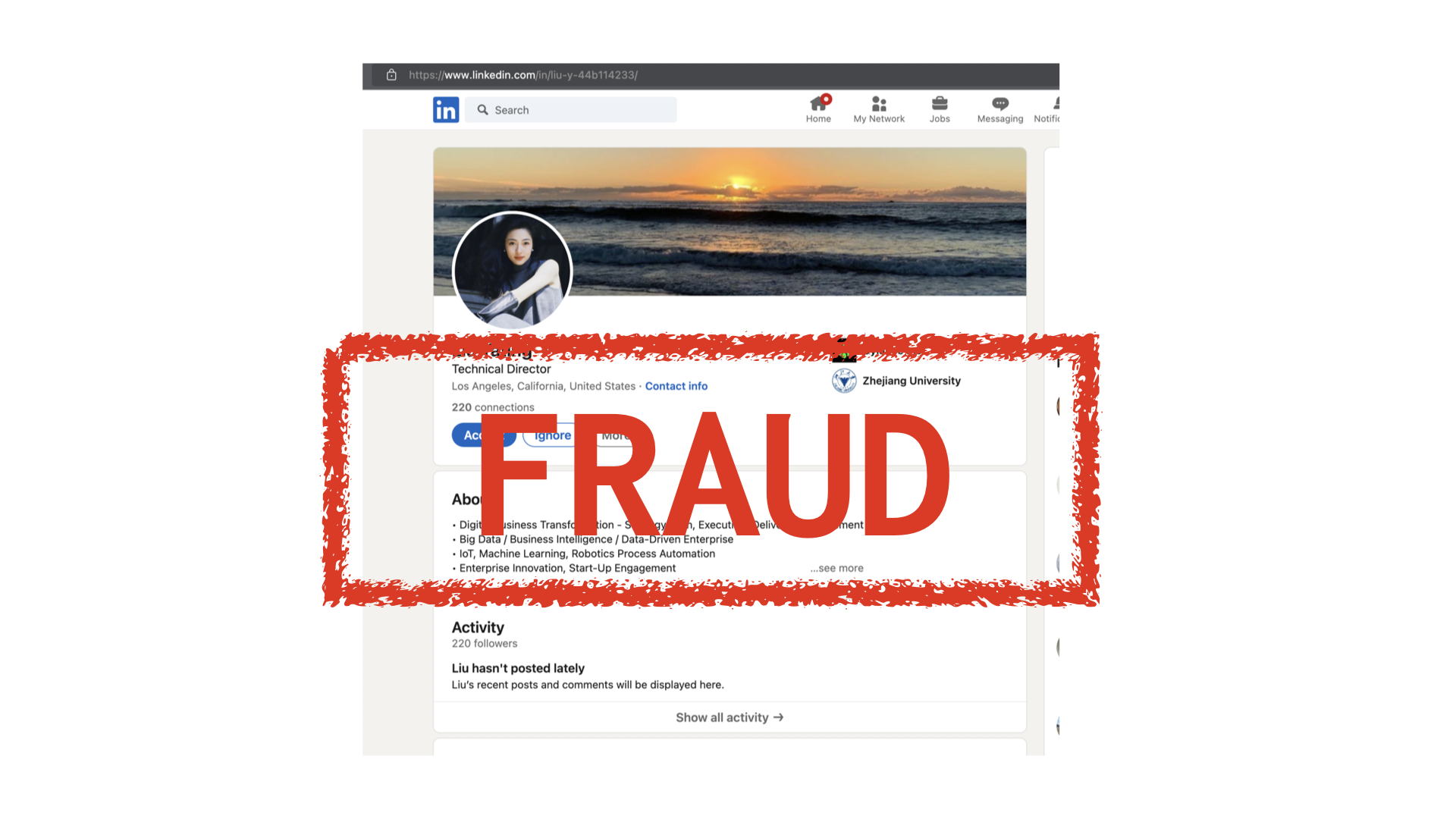
On Linkedin, I believe many of us have received such “please add me to your professional network” requests:
- job titles like “Technical Director” or “Technical Advisor”
- profile pictures are all Asian ladies, most of them are Photoshop retouched
- they work in tech industry; instead of
MAANGcompanies, their companies are generally well known in each industrial category. - they graduated from some top rank universities, mostly in China
- no much recent activity on Linkedin
and a few other features that I hope everyone notices. I believe Linkedin’s fraud detection team has worked very hard, but such account fraud and spam attacks must be the work of a sophisticated attacker, because each feature is carefully crafted to be confusing enough as a single feature or in combination. Can we, as Linkedin users, help Linkedin in combating such fraud? We can use it as an example of robust feature engineering.
Features that appear to be so obvious may not be good features. It is a hard lesson learned in cybersecurity because such features do not ensure its robustness for classification in a dynamic environment. For example, one can deploy a feature such as “if the job title contains Technical Director” to detect such fraud accounts. Despite the model’s false positive rate, the attackers can simply monitor the fraud effectiveness to determine that “Technical Director” is no longer a good title and can quickly change to another one. Such feature drift as a result of an attack policy change can drag the defense team into a mud pit fight.
The same is true for the other features listed above. Do we want to create a deep learning model to detect if a profile picture has been Photoshopped? No, GAN can be used by attackers to generate new portrait images that no one can detect. Do we want to gather all of the good companies in each industrial category? No, the attackers can steal company names from legitimate resumes. Do we intend to shut down all Chinese universities? Universities are not guilty. Do we want to validate the recent Linkedin activity? No, the attackers can join numerous Linkedin groups and spam them, posing a larger problem than account fraud. So, what are our options?
In my previous post about feature engineering, I cited a comment:
“Only algorithms care about right or wrong, security is about cost.”
One approach to robust feature engineering for adversarial environments is to increase the cost of attack so that the features are either difficult to change or impossible to change. Let’s think like an attacker and figure out “what makes my job difficult”: more engineering work, a longer payback loop, data I can’t access, and so on.
The profile URL pattern, for example, provides a small bar-raising feature. The profile ID ‘liu-y-44b114233’ is shown in the sample screenshot as a default ID generated by the onboard system, so “If using default ID” as a feature can force attackers to code their own profile IDs, which adds to the attacking cost.
Another example is recent connection vs lifetime connection, which suggests a recent connection spike to be more fraudulent. Because the account fraud and spam business prefers quick turnover, attackers focus on short-term gain. Features such as “new user pattern,” “connection request rate,” “connection approval rate,” and “connection patterns over time” can slow down an attack and discourage attackers.
Leveraging data that attackers do not have access to can generate new ideas. For example, attackers cannot see the overall Linkedin user pattern, but Linkedin can via the global connection graph. Attackers seek more connections, so they begin with people who always approve new connections for whatever reason, similarly in cybersecurity, machines with unpatched vulnerabilities can easily be infected with new malware. The model can leverage this “user-item” interaction feature from graph for classification by labeling “easy to approve” users with historical fraud detection data. The same concept can be applied to the user’s fingerprint versus the requesting connection fingerprint: do all request connections share the same profile patterns? Trust me, graph data features can significantly raise the bar for attack.
Certainly, robust feature engineering is a broad topic with many aspects to combat “drift” from data, including feature engineering, seasonal effect, black swan, adversarial attack, and so on. Furthermore, fraud detection cannot be accomplished by a single machine learning model. It necessitates a data system, feature, model, and operation. Aside from great feature engineering and models, the system should collect user feedback for the model, such as “ignore because I think it is fraud,” and improve the operational process, such as fraud prediction with reasons.